

Pour que votre site web soit classé dans les résultats de recherche, Google doit l'explorer et l'indexer. Ce processus permet à Google de découvrir le contenu de votre site web, de comprendre ce qu'il contient et d'afficher vos pages dans les résultats de recherche appropriés.
Pour aider Google à explorer vos pages, vous devez utiliser un fichier robots.txt. Sur cette page, nous répondrons à toutes les questions brûlantes que vous vous posez sur les fichiers robots.txt :
- Qu'est-ce qu'un fichier robots.txt ?
- Quelle est l'importance de robots.txt ?
- Comment mettre en œuvre le fichier robots.txt ?
Poursuivez votre lecture pour en savoir plus sur robots.txt !
Qu'est-ce que le fichier robots.txt ?
Robots.txt est un fichier qui indique aux moteurs de recherche les pages à explorer et celles à éviter. Il utilise les instructions "allow" et "disallow" pour guider les robots vers les pages que vous souhaitez voir indexées.
Exemple de Robots.txt
À quoi ressemble un fichier robots.txt ? Chaque fichier robots.txt est différent en fonction de ce que vous autorisez ou non Google à explorer.
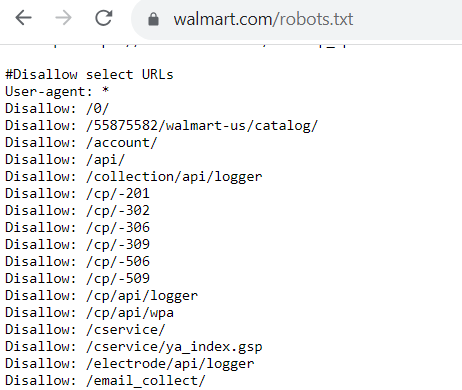
Si vous autorisez les robots à explorer certaines pages, le code ressemblera à ceci :
User-agent: Googlebot
Allow: /
L'agent utilisateur est le robot que vous autorisez (ou non) à explorer votre site web. Dans cet exemple de fichier robots.txt, vous autorisez Googlebot à explorer les pages de votre site web.
Si vous ne voulez pas qu'un robot explore les pages de votre site web, le code ressemble à ceci :
User-agent: Bingbot
Disallow: /
Pour cet exemple de robots.txt, ce code indique que le Bingbot ne peut pas explorer les pages d'un site web.
Pourquoi le fichier robots.txt est-il important ?
Pourquoi le fichier robots.txt est-il important ? Pourquoi devez-vous vous préoccuper de l'intégration de ce fichier dans votre site web ?
Voici quelques raisons pour lesquelles le fichier robots.txt est essentiel à votre stratégie d'optimisation des moteurs de recherche (SEO) :
1. Il évite à votre site web d'être surchargé
L'une des principales raisons de mettre en place un fichier robots.txt est d'éviter que votre site web ne soit surchargé de requêtes d'exploration.
La mise en place du fichier robots.txt permet de gérer le trafic de crawl sur votre site web afin qu'il ne soit pas trop important et qu'il ne ralentisse pas votre site web.
Google envoie des requêtes pour explorer et indexer les pages de votre site web - il peut envoyer des dizaines de requêtes à la fois. La mise en place du fichier robots.txt permet de gérer le trafic de crawl sur votre site web afin d'éviter qu'il ne le submerge et ne le ralentisse.
Un site web lent a des conséquences négatives sur le référencement, car Google veut proposer des sites web à chargement rapide dans les résultats de recherche. En mettant en place le fichier robots.txt, vous vous assurez donc que Google ne surcharge pas et ne ralentit pas votre site web lorsqu'il l'explore.
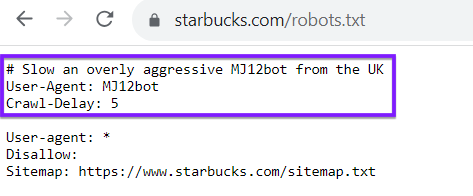
N'oubliez pas que votre fichier robots.txt n'est pas réservé aux robots d'indexation des moteurs de recherche tels que Google ou Bing. Vous pouvez également utiliser votre fichier robots.txt pour diriger les robots d'autres sites web. Prenons l'exemple du fichier robots.txt de Starbucks, qui retarde l'arrivée d'un certain robot :
2. Il vous aide à optimiser votre budget d'exploration
Chaque site web dispose d'un budget d'exploration, qui correspond au nombre de pages que Google explore dans un laps de temps donné. Si votre site web contient plus de pages que ne le permet votre budget d'exploration, certaines pages ne seront pas indexées, ce qui signifie qu'elles ne pourront pas être classées.
Bien que votre fichier robots.txt ne puisse pas empêcher l'indexation des pages, il peut indiquer aux robots d'indexation où ils doivent passer leur temps.
L'utilisation du fichier robots.txt vous permet d'optimiser votre budget d'exploration. Il permet de guider les robots de Google vers les pages que vous souhaitez voir indexées. Bien que votre fichier robots.txt ne puisse pas empêcher l'indexation de certaines pages, il peut permettre aux robots de se concentrer sur les pages qui ont le plus besoin d'être indexées.
3. Il permet d'empêcher les robots d'explorer les pages non publiques.
Chaque entreprise possède sur son site web des pages qu'elle ne souhaite pas voir apparaître dans les résultats de recherche, comme les pages de connexion et les pages dupliquées. Le fichier Robots.txt peut aider à empêcher ces pages d'apparaître dans les résultats de recherche et les bloquer pour les robots d'exploration.
6 conseils pour réussir à utiliser robots.txt pour le référencement
Vous êtes prêt à intégrer un fichier robots.txt à votre site web ? Voici 6 conseils pour vous aider à réussir :
1. Veillez à ce que toutes vos pages importantes puissent être explorées.
Avant de créer votre fichier robots.txt, il est important d'identifier les pages les plus importantes de votre site web. Vous voulez vous assurer que ces pages sont explorées, afin qu'elles puissent être classées dans les résultats de recherche.
Avant de créer votre fichier robots.txt, documentez les pages importantes que vous souhaitez autoriser les robots de recherche à explorer. Il peut s'agir de pages telles que votre :
- Pages de produits
- A propos de nous
- Pages d'information
- Articles de blog
- Page de contact
2. N'utiliser chaque user-agent qu'une seule fois
Lorsque vous créez votre fichier robots.txt, il est important que chaque user-agent ne soit utilisé qu'une seule fois. Cette façon de procéder permet de conserver un code propre et organisé, en particulier si vous souhaitez interdire un grand nombre de pages.
Voici un exemple de fichier robots.txt montrant la différence :
User-agent: Googlebot
Disallow: /pageurl
User-agent: Googlebot
Disallow: /loginpage
Imaginez maintenant que vous deviez le faire pour plusieurs URL. Cela deviendrait répétitif et rendrait votre fichier robots.txt difficile à suivre. Il est préférable de l'organiser comme suit :
User-agent: Googlebot
Disallow: /pageurl/
Disallow: /loginpage/
Avec cette configuration, tous les liens interdits sont organisés sous l'agent utilisateur spécifique. Cette approche organisée vous permet de trouver plus facilement les lignes que vous devez ajuster, ajouter ou supprimer pour des robots spécifiques.
3. Utiliser de nouvelles lignes pour chaque directive
Lorsque vous créez votre fichier robots.txt, il est essentiel de placer chaque directive sur sa propre ligne. Là encore, cette astuce vous permettra de gérer plus facilement votre fichier.
Ainsi, chaque fois que vous ajoutez un agent utilisateur, il doit être sur sa propre ligne avec le nom du bot. La ligne suivante doit contenir l'information "disallow" ou "allow". Chaque ligne d'interdiction suivante doit être indépendante.
Voici un exemple de ce qu'il ne faut pas faire dans le fichier robots.txt :
User-agent: Googlebot Disallow: /pageurl/ Disallow: /loginpage/
Comme vous pouvez le constater, il est plus difficile de lire votre fichier robots.txt et de savoir ce qu'il contient.
Si vous faites une erreur, par exemple, il sera difficile de trouver la bonne ligne à corriger.
Le fait de placer chaque directive sur sa propre ligne facilitera les modifications ultérieures.
4. Veillez à utiliser des cas d'utilisation appropriés
S'il y a une chose à savoir sur le fichier robots.txt pour le référencement, c'est qu'il est sensible à la casse. Vous devez vous assurer que vous utilisez les cas d'utilisation appropriés, afin qu'il fonctionne correctement sur votre site web.
Tout d'abord, votre fichier doit être étiqueté comme "robots.txt" dans ce cas d'utilisation.
Deuxièmement, vous devez tenir compte des variations de capitalisation des URL. Si vous avez une URL qui utilise toutes les majuscules, vous devez la saisir comme telle dans votre fichier robots.txt.
5. Utiliser le symbole "*" pour donner des indications
Si vous avez plusieurs URL sous la même adresse et que vous voulez empêcher les robots d'explorer, vous pouvez utiliser le symbole "*", appelé caractère générique, pour bloquer tous ces URL en même temps.
Supposons par exemple que vous souhaitiez interdire toutes les pages relatives aux recherches internes. Au lieu de bloquer chaque page individuellement, vous pouvez simplifier votre fichier.
Au lieu de ressembler à ceci :
User-agent: *
Disallow: /search/hoodies/
Disallow: /search/red-hoodies/
Disallow: /search/sweaters
Vous pouvez utiliser le symbole "*" pour le simplifier :
User-agent: *
Disallow: /search/*
Cette étape permet d'empêcher les robots des moteurs de recherche d'explorer toutes les URL situées dans le sous-dossier "search". L'utilisation du symbole du caractère générique est un moyen facile d'interdire des pages par lots.
6. Utiliser le "$" pour simplifier le codage
Il existe de nombreuses astuces de codage que vous pouvez utiliser pour faciliter la création de votre fichier robots.txt. L'une d'entre elles consiste à utiliser le symbole "$" pour indiquer la fin d'une URL.
Si vous souhaitez interdire des pages similaires, vous pouvez gagner du temps en utilisant le "$" pour l'appliquer à toutes les URL similaires.
Par exemple, imaginons que vous souhaitiez empêcher Google d'explorer vos vidéos. Voici à quoi pourrait ressembler ce code si vous faites chacune de ces opérations :
User-agent: Googlebot
Disallow: /products.3gp
Disallow: /sweaters.3gp
Disallow: /hoodies.3gp
Au lieu de les placer sur des lignes distinctes, vous pouvez utiliser le "$" pour les interdire tous. Voici à quoi cela ressemble :
User-agent: GooglebotDisallow: /*.3gp$
L'utilisation de ce symbole indique aux robots d'exploration que les pages se terminant par " .3gp " ne peuvent pas être explorées.
Élargissez vos connaissances en matière de référencement
L'ajout du fichier robots.txt à votre site web est essentiel pour aider Google à explorer vos pages sans le surcharger. C'est l'un des aspects qui vous aideront à faire du référencement de manière efficace.
Vous cherchez plus d'informations sur le référencement de la part des experts ? Consultez notre blog pour en savoir plus sur ce qu'il faut faire pour avoir une stratégie de référencement réussie !
Ne ratez pas le test le plus important de votre site web
Obtenez gratuitement une carte de score SEO de votre site web en moins de 30 secondes.
Ensemble, obtenons des résultats 
Écrivains
